英伟达适配DeepSeek-V4 AI模型,开箱性能超150 tokens/sec/user
炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
(来源:IT之家)
IT之家 4 月 25 日消息,英伟达今天(4 月 25 日)发布博文,宣布其 NVIDIA Blackwell 平台已适配 DeepSeek-V4-Pro 与 DeepSeek-V4-Flash 两款模型,开发者可通过 NVIDIA NIM 微服务下载部署,或利用 SGLang 与 vLLM 框架进行定制化推理。
英伟达在博文指出,DeepSeek-V4-Pro 拥有 1.6T 总参数量与 49B 激活参数,定位高级推理任务;DeepSeek-V4-Flash 版本则为 284B 总参数量与 13B 激活参数,主打高速高效场景。
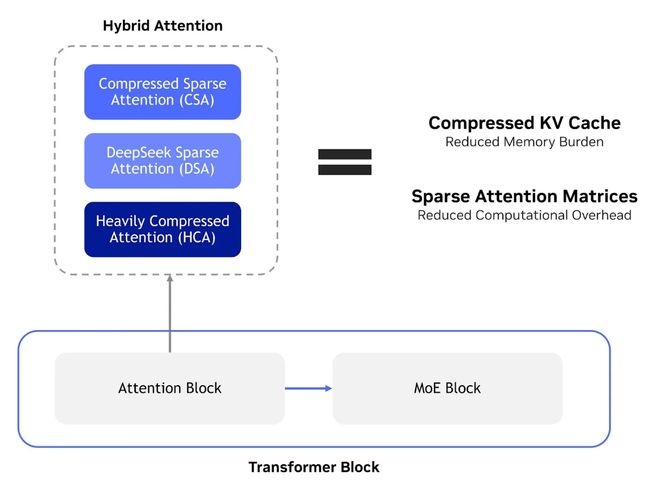
两款模型均支持 100 万 Token 上下文窗口与最高 38.4 万 Token 输出长度,覆盖长文本编码、文档分析等核心应用,并采用 MIT 开源协议。
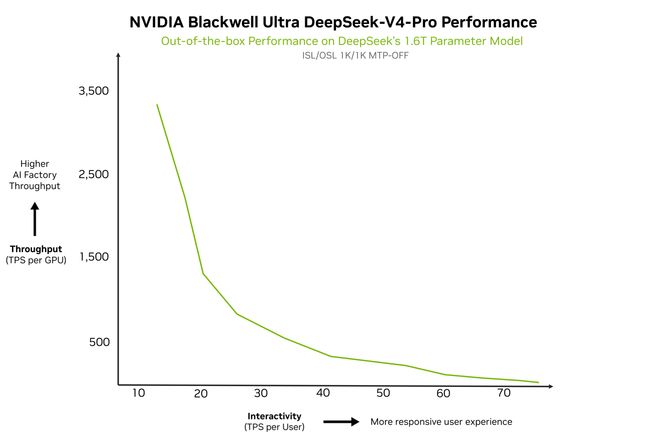
实测数据显示,DeepSeek-V4-Pro 在 NVIDIA GB200 NVL72 上开箱即用性能超 150 tokens / sec / user,借助 vLLM 的 Day 0 配方,开发者可在 Blackwell B300 上快速部署。随着 Dynamo、NVFP4 及 CUDA 内核的深度优化,预期性能将进一步提升。
部署生态方面,开发者可通过 NVIDIA NIM 微服务下载部署,或利用 SGLang 与 vLLM 框架进行定制化推理。SGLang 提供低延迟、均衡及最大吞吐量三种配方;vLLM 则支持多节点扩展至 100 个以上 GPU,具备工具调用与推测解码能力。

相关文章