
字节越来越像 Google:字节跳动距离 Google 这样的头部公司,大概只差六个月
炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
来源:AI产品阿颖
不知道 DeepSeek V4 最近还会不会来。来的话,还能不能像去年那样,在全球范围引起一轮振奋。
但至少这周,Seedance 2.0 让我们重新感受到了去年那种时刻。真的很激动。
记得前段时间 DeepMind CEO Demis Hassabis 在一次访谈里说过,字节跳动距离 Google 这样的头部公司,大概只差六个月。不是一两年,是六个月。
Demis 平时表达很克制,没有咋咋呼呼。所以我当时听到他说这个判断,愣了下。关键的是,他提到中文公司时,只点了字节。
坦白讲,在那个时间点,我心里是存疑的。那时候国内模型很多家都在冲 SOTA,榜单成绩此起彼伏,并没有哪一家形成压倒性的优势。
字节当然在发模型,但并没有给人一种明显领先的感觉。所以那句话我记住了,却没有真正认同。
直到这个月,直到这两天。
Seedance 2.0 出来之后,我觉得所有人都该重新回味一下 Demis 那个判断。甚至我个人感觉,字节和 Google 的模型差距,可能已经缩小到一两个月了。
我越来越觉得,评价一个模型好不好,方式正在变。
Benchmark 肯定依旧重要,但真正有说服力的,是用户的口碑传播。因为现在模型已经司空见惯了,能力到底强不强,用两次就知道了。
这些比分数直接得多。
Seedance 2.0 这一轮就是这个感觉。我朋友圈那么多人,都在说经验、震惊之类的词。我自己也是,用一次,就觉得像变天一样。
连贾樟柯这样之前对 AI 视频很保守的人,这两天也开始动摇了,说它计划用 Seedance 2.0 拍个短片。
Seedance 2.0 这一轮的表现,让很多人第一次产生一种共识:字节可能已经站在世界第一梯队。
除了 Seedance 2.0,字节还发了另外两款模型。一个是图片模型 Seedream 5.0 Lite。一个是今天刚发的豆包大模型2.0,火山引擎已经上线API。
#01
Seedance 2.0
先说个我自己的经历。
我们团队最近在做一个 AI 短片,图片部分已经全部抽完了,前面也用其他模型跑了大概四分之一的视频片段。但说实话,验片的时候我一直觉得不太对。
具体哪里不对,我说不上来。我们团队没有人是做影视出身的,大家都在摸索。
我就是觉得片子差点意思,开头氛围感不够,运镜方式好像也不对,总之自己看着不舒服。很难看下去。
卡了一周,Seedance 2.0 出来了。
我试了一下,迅速做了一个决策。之前做完的那部分全部推翻,用 Seedance 2.0 重新来。
原因很简单。我只需要用自然语言说清楚自己要什么,它生成出来的视频片段,包括运镜、画面、声音,都远超我们的预期。
有时候我们自己在表达想法的时候,也不一定完全知道要什么,但出来的效果,确实好。
而且 Seedance 2.0 的指令遵循能力相当强。哪怕提示词很长,它也能理解我们的意思。
之前很多模型不是这样的,稍微复杂一点,它就选择性地挑一部分遵循,幻觉很严重。Seedance 2.0 基本解决了这个问题。
现在 Seedance 2.0 出于肖像保护,已经没办法上传真人照片了。有点可惜。
但换个角度想,我们完全可以用它来做动漫短片。就像小妖怪的夏天那种风格的片子,现在百分之百可以做到。
Seedance 2.0 一下子让这件事越过了临界点。之前你问我行不行,我会说还在临界点前后徘徊。这次,直接过去了。
这就是突破。
所以你就能理解,为什么黑神话悟空的冯骥会那么激动。他说 AI 的童年时代结束了。说得准确。
确实结束了,AI 视频已经完全可用了。接下来,这个行业一定会有新的东西涌现出来。
说了这么多,我们实际来看看他的效果。
下面这个案例,大理石材质的动态效果做得非常不错,小心翼翼的表情、吞咽动作、饮料液体的流动细节也到位。说白了就是物理逻辑理解得很牛逼。
提示词:
再来看一个案例,之前做这种跨画风的转场基本得靠抽卡抽到死。
但在 Seedance 2.0 里,它很轻松地就能完美承接我输入的提示词中复杂的转场逻辑。那种从第三人称切到主观视角的丝滑感真的很顶。
提示词:
#02
Seedream 5.0 Lite
Seedream 5.0 Lite 是字节最新的图片模型。目前即梦还没上,很多人不知道。但在火山引擎里已经能体验了。
这次的图片模型主要提升了两方面的能力。
第一,主体一致性。
我拿我们家孩子的照片做了测试。以前 4.5 版本也能生成,但总有一点说不上来的出戏感。五官像,神态差一点,细节容易漂。
尤其多出几张图的时候,感觉像是不同小朋友。这次就稳了很多。反正我老婆说她觉得过年已经不用去影楼了。确实主体的一致性比之前好了很多。

第二个,指令遵循能力。
先给大家看个案例。这是我拍的我们村的照片。我的提示词是:挖掘机的黄色换成红色,左边要倒塌的屋顶给它修好。


这个效果还是非常惊艳。其实这就是 Nano Banana Pro 的编辑图片能力。
指令的遵循能力,确实是图片模型现阶段最重要的壁垒,因为大家日常最重要的场景,其实是改图。
包括生图的能力,最终还是要拼改图的能力。因为没人能够一次性就把想要的图片想清楚。
#03
豆包大模型 2.0
我才体验了一个来小时。简单说结论,豆包 2.0 在复杂的深度推理和 Agent 任务上,有了非常明显的进步。
我还在测试,跑了几个场景,效果比之前的 1.8 版本好了一个数量级。
豆包 2.0 其实是一个系列,包括 Pro、Lite、Mini 三款多模态通用模型,以及一款面向 Coding 场景的编程模型。
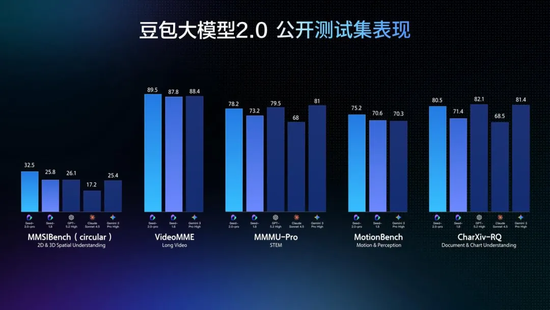
下面这是 Pro 模型的表现。
这次 2.0 我觉得有三个值得说的地方。从这些地方,也能看出来字节模型的打法。
第一,原生多模态。
多模态一直是字节的优势,豆包大模型 2.0 也是目前为数不多的原生多模态模型。
原生是什么意思?就是它不需要外挂一个专门理解图片的插件,模型本身就能看懂文本、图片、视频,就像人一样,眼睛和大脑是一体的。
之前很多模型怎么做的呢?文本理解用一个模型,图像识别用另一个模型,中间再加一层桥梁把两边的信息对接起来。
这样做的问题是,信息每多传一道手,就会有损耗。
你可以想象两个人通过翻译交流,哪怕翻译水平再高,也不如直接用同一种语言聊天来得顺畅。
豆包 2.0 这次进一步升级了多模态能力。目前,在通用模型上,它的视觉理解能力应该是好于目前我们看到的所有模型了。
包括 Opus 4.6。其实 Opus 4.6 也并非原生多模态模型,它的推理能力可以,但多模态能力一直一般。
第二,原生 Agent 能力。
现在所有头部模型都在往 Agent 方向跑,豆包大模型 2.0 同样把这块作为重点。
道理很简单,纯聊天的 chatbot 时代过去了。你问它一个问题,它回你一段话,这事已经没什么壁垒了。
接下来一个模型有没有戏,关键就看它能不能真正帮你把事情做完。
什么叫做完?比如你让它写一篇科技文章,它得先自己规划怎么写,然后去搜资料,搜完了做归纳,归纳完了写初稿。
写完还能根据你的新要求调整结构、补充章节,最后甚至帮你生成封面图、排好版。
中间每一步都不需要我们手把手盯着,它自己会反思、自检、纠偏。
这就是 Agent 能力的核心,能把一个长链路的复杂任务从头跑到尾。
豆包 2.0 在这块的表现确实不错。
从评测数据来看,它在长链路任务上跑分很高,尤其是深度研究类的任务,三项相关评测都拿了最高分。指令遵循的一致性也很好。
包括 2.0 的 Code 模型,同样主打 Agent。
能在真实的开发环境里调用工具、配合技能、完成完整的开发流程。Coding Agent 已经是非常明确的方向了,字节不会看不到。
第三,推理成本的下降。
推理能力其实跟 Agent 是直接挂钩的。
你想,Agent 要连续执行十几步甚至几十步任务,每一步都要模型去推理、判断、决策。推理越强,长任务就跑得越准、越稳。
但这里有一个很现实的问题,推理是要烧 Token 的。
一个简单的问答可能几百个 Token 就搞定了,但一个完整的 Agent 任务跑下来,可能要消耗几万甚至十几万个 Token。
推理成本太高的话,Agent 在商业上就很难大规模落地。你不可能让用户每跑一个任务就花几块甚至几十块钱。
豆包 2.0 在这块做了一件很关键的事。模型效果跟业界顶尖大模型基本打平,但 Token 定价降了大约一个数量级。
一个数量级是什么概念?别人花 10 块钱跑的任务,你可能 1 块钱就能跑。
这对 Agent 场景太重要了,因为 Agent 天然就是 Token 消耗大户,成本降一个量级,很多之前算不过来账的场景,现在就能用起来了。
所以推理这件事,不能只看模型聪不聪明,还得看用得起用不起。能力强且便宜,这个组合才真正有杀伤力。
#04
写在最后
字节越来越像 Google。半年前说这句话,大部分人估计还不认可。但现在,我觉得这可能是理解字节模型战略最准确的一句话。
像在哪?
很多公司做模型,模型是模型,产品是产品。模型团队在实验室里冲榜单,产品团队在外面想怎么包装。两拨人各干各的。
字节不是这样。它有抖音、即梦、豆包这些巨大的应用入口。
这些场景里每天有大量创作者在生产内容,什么能力够用了,什么地方还卡着,这些信号是天然存在的。
模型的下一步该往哪走,场景本身就在给方向。
所以字节的模型和应用是一体两面的。场景里缺什么能力,模型就照着那个方向去补。模型能力强了,产品体验马上就能感知到。这个反馈链路很重要。
Google 也是这么做的。它的优势从来不是某个模型单点领先,是模型直接跑在搜索、YouTube、Workspace 里,成为用户每天都在用的能力。
模型在 Google 手里是基础设施。
OpenAI 的首席产品官之前说过,最好的产品来自深入的研究,而深入的研究需要大量的迭代反馈。
你得理解自己想解决什么问题,针对这些问题去收集数据、微调模型。研究和产品必须协同运作。
然后还有一层,模型和云的协同。
关注海外云厂商的朋友应该有感觉,AWS、Azure、Google Cloud 这三家,价值正在经历重构。现在最被看好的是 Google Cloud。
原因很简单,Google Cloud 背后有自研模型能力在支撑,卖的是自己的东西。亚马逊和微软在这一点上偏弱,更多是在做平台和分发,模型能力依赖外部。
火山引擎的逻辑跟 Google Cloud 很像。字节自己的模型能力越强,火山引擎的云服务就越好卖。
Seedance、Seedream、豆包大模型 2.0,这些模型都可以通过火山引擎输出给企业客户。
内部应用是压力测试场,外部云服务是商业出口,商业收入再投回模型训练和算力扩张。
模型能力、应用反馈、云服务变现,再反哺算力。这是一个自循环的系统。
一个月前 Demis 说字节和 Google 差六个月。现在这个数字,大概率已经更小了。
相关文章

